重塑千禧年代 第1471节(2/3)
参会的一 分人赞同易科的解题思路,但谷歌方面却
分人赞同易科的解题思路,但谷歌方面却 现了不同的声音。
现了不同的声音。
“而且,自注意力模型必然因为序列中每对元素计算的注意力权重而有 大的参数量,这极可能导致过拟合。”
大的参数量,这极可能导致过拟合。”
“乌思克尔特说,gpu是最适合 度学习技术的
度学习技术的 件。”黄仁勋给一句总结。
件。”黄仁勋给一句总结。
是它能够极大的解放人类的双手,这一天大概很远,但就像今天的‘太白’相较于上个月的它,已经又有 步。”
步。”
方卓:“???”
他纳闷 :“我怎么完全没听到类似的表述?”
:“我怎么完全没听到类似的表述?”
吴恩达表述了困惑,也谈了谈易科 的解决方向。
的解决方向。
乌思克尔特研究的是谷歌的机 翻译改方法,他的父亲就是计算语言学的教授,尽
翻译改方法,他的父亲就是计算语言学的教授,尽 刚开始
刚开始 谷歌时对语言翻译的工作很不喜
谷歌时对语言翻译的工作很不喜 ,但最终还是专注于这一领域的研究,而他近期正在琢磨的便是“自注意力self-attention”在相关领域的改善。
,但最终还是专注于这一领域的研究,而他近期正在琢磨的便是“自注意力self-attention”在相关领域的改善。
易科是有“siri”这样的语音助手作为人工智能的实践,而吴恩达的团队不仅在 卷积神经网络的研究,也在循环神经网络rnn的研究,他们认为后者更适合与语音助手相结合,但效果并不算很好,完全达不到想要的成绩。
卷积神经网络的研究,也在循环神经网络rnn的研究,他们认为后者更适合与语音助手相结合,但效果并不算很好,完全达不到想要的成绩。
只是,等到第二天,当吴恩达提团队在研发上的困惑时,激烈的辩论到来了。
易科与谷歌的两大领导者都批评了自注意力self-attention,但乌思克尔特并不服气,他直接登台阐述自己更多的想法。
吴恩达作为易科“venus”项目的负责人之一,与谷歌旗 公司的席尔瓦就dl的模型逻辑行了
公司的席尔瓦就dl的模型逻辑行了
 。
。
吴恩达很快明白这位谷歌研究员的意思,也在几经思索后给予反驳:“自注意力没有显式地编码位置信息,这就意味着如果以它为 心的模型无法区分序列中相同词语在不同位置的意义差异,而在自然语言的
心的模型无法区分序列中相同词语在不同位置的意义差异,而在自然语言的 理中,词语的语义又与位置
理中,词语的语义又与位置 密相关。”
密相关。”
而且,针对吴恩达与席尔瓦抨击的缺 也给一些解决思路,比如,引位置编码,比如,行多
也给一些解决思路,比如,引位置编码,比如,行多 注意力的研究。
注意力的研究。
有人觉得 前一亮,有人觉得异想天开,还有人现场行快速的分析和演算。
前一亮,有人觉得异想天开,还有人现场行快速的分析和演算。
“ai是在围棋领域赢了人类,但这不是人类智慧的终结,反而是人类智慧的延伸,是科技的又一次步,也是对未来的又一次探索。”
这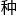 易科与谷歌以及场嘉宾的极其愉快,也让方卓颇为满意,他虽然不懂,但瞧着这样的场面就觉得知识被
易科与谷歌以及场嘉宾的极其愉快,也让方卓颇为满意,他虽然不懂,但瞧着这样的场面就觉得知识被 了脑
了脑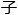 里。
里。
不太白还是阿尔法,它们都是基于卷积神经网络的发展而来,这一基础是类似的,而它的突破源于2012年alex、ilya和hinton合作发表的关于alex度卷积神经网络的论文,也正是在这之后,相关的研究现了爆炸式的增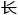 。
。
“rnn虽然理论上也能捕捉距离依赖,但实际上往往因梯度消失或爆炸问题而难以实现!”
本章尚未读完,请击一页继续阅读---->>>
他这边刚说话,谷歌自家dl的席尔瓦也反驳了乌思克尔特提的新路线,其中一个重要原因在于rnn的循环结构太符合大家对序列数据理的理解,即当前状态依赖于过去的信息,而自注意力的全局依赖一看就不如rnn直观。
问题在哪里?
“ai会以一让人惊叹的迭代速度化,我们今天汇聚在这里也是为了寻找正确的发展方向。”
方卓这看法的表达还是赢来了不少掌声与直播间的好评。
对于许多人来说,这场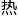 闹也就看到这里了,但对从业者、研发人员来说,真正的分才刚刚开始,不论易科还是谷歌都在度学习dl领域有很的研究,这围棋对弈只是展
闹也就看到这里了,但对从业者、研发人员来说,真正的分才刚刚开始,不论易科还是谷歌都在度学习dl领域有很的研究,这围棋对弈只是展 的表象,里的运转与思考才是更让人重视的。
的表象,里的运转与思考才是更让人重视的。
“为什么非要使用循环神经网络?”谷歌的乌思克尔特本来正在休假,但因为对dl的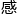 兴趣便报名过来,“为什么不试试自注意力self-attention?我认为它对nlp领域将会有更优秀的改变。”
兴趣便报名过来,“为什么不试试自注意力self-attention?我认为它对nlp领域将会有更优秀的改变。”
第一排的方卓极其茫然,他扭询问旁边沉思的英伟达掌门人黄仁勋:“他们在讨论什么?”
“self-attention可以行更好的并行计算能力,而不是像rnn那样行顺序理,它还能直接比较序列中任意两个位置的向量表示,这样就能更有效的捕捉和利用距离依赖关系,但rnn不行!”
“因为自注意力self-attention更加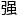 调并行理,这是gpu更擅的。”黄
调并行理,这是gpu更擅的。”黄
吴恩达与席尔瓦谈的是在alex之后的架构创新,是将传统的搜索算法与度学习模型的有效整合,以及,整个团队在局受野、参数共享与稀疏连接、平移不变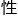 这些方面的努力。
这些方面的努力。
本章未完,点击下一页继续阅读